-
方案开源地址:季军方案
-
比赛数据在此:https://pan.baidu.com/s/1Lnda54VN6IuEYF9GMxAk3g
提取码:9ttp
-
队伍名称: 优生801
第一部分:赛题解读
1、赛题背景
目前,京东零售集团第三方平台签约商家超过21万个,实现了全品类覆盖,为维持商家生态繁荣、多样和有序,全面满足消费者一站式购物需求,需要对用户购买行为进行更精准地分析和预测。基于此,本赛题提供来自用户、商家、商品等多方面数据信息,包括商家和商品自身的内容信息、评论信息以及用户与之丰富的互动行为。参赛队伍需要通过数据挖掘技术和机器学习算法,构建用户购买商家中相关品类的预测模型,输出用户和店铺、品类的匹配结果,为精准营销提供高质量的目标群体。
2、数据理解
用户对品类下店铺的购买预测的数据包括用户行为、商品评论、商品信息、店铺信息、用户信息5个数据表。由于需要预测的是用户未来7天内对某个目标品类下某个店铺的购买意向,因此时间的相关信息显得尤为重要。
3、目标解读
本次大赛通过给出2018-02-01到2018-04-15两个半月内用户U的浏览、购买、收藏、评价、加购等数据信息,需要参赛者预测两个半月后的一周时间(4.16-4.22)可能购买的用户U以及对应购买的品类C和店铺S。
大赛可分为两个部分,一个是需要预测在考察周内用户的购买品类,一个是对应品类下的店铺预测。对每个用户的预测包括用户-品类和相应品类下店铺两个方面,评分采用加权的方式。此处可以分成两个任务去进行分别预测,但是出于对简化问题复杂度的考虑,这里直接合并作为一个二分类任务进行预测。
4、赛题评分
参赛者提交的结果文件中包含对所有用户购买意向的预测结果。对每一个用户的预测结果包括两方面:
(1)该用户2018-04-16到2018-04-22是否对品类有购买,提交的结果文件中仅包含预测为下单的用户和品类(预测为未下单的用户和品类无须在结果中出现)。评测时将对提交结果中重复的“用户-品类”做排重处理,若预测正确,则评测算法中置label=1,不正确label=0。
(2)如果用户对品类有购买,还需要预测对该品类下哪个店铺有购买,若店铺预测正确,则评测算法中置pred=1,不正确pred=0。
对于参赛者提交的结果文件,按如下公式计算得分:score=0.4F11+0.6F12
此处的F1值定义为:

其中:Precision为准确率,Recall为召回率; F11 是label=1或0的F1值,F12 是pred=1或0的F1值。
5、赛题难点
本次比赛分为A,B榜,但是两个榜都是采用同一套数据集。通过EDA分析可知,数据集存在很多噪声,例如加购数据存在大量缺失,浏览数据也存在两天的缺失,2月份数据受春节影响流量异常。如何建模尽可能达到最大的预测准确性。我们将本次比赛的难点归纳为如下几点。
(1)本次比赛的label需要自己构建, 如何建模使我们能在给定的数据集上达到尽可能大的预测准确性,是本次比赛考虑的关键点之一。
(2)对于训练集不同时间段的选取对最终结果都很造成一定的影响,如何选用时间段,让训练集分布和测试集分布类似,也是本次比赛的关键之一。
(3)如何刻画每个时间段的时序特点,使其能够捕捉数据集的趋势性,周期性,循环性。
(4)给来的数据集存在太多影响因素,比如加购数据缺失,浏览数据部分缺失,春节流量异常,节后效应等,所以该如何选取训练集&保证模型稳定的情况。
(5)模型预测出来是概率文件,如何确定划分正负样本的概率阈值,如何确定最优的提交结果数,也是本次比赛不可忽略的关键点之一。
第二部分:算法核心设计思想
1、数据探索分析
1.1基础数据信息观察
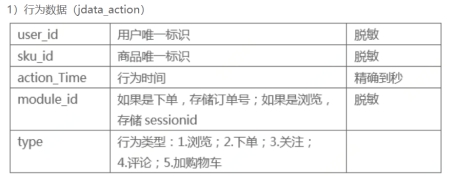
1.1.1 jdata_action数据表
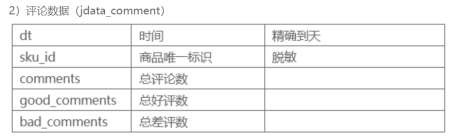
1.1.2 jdata_comment 数据表
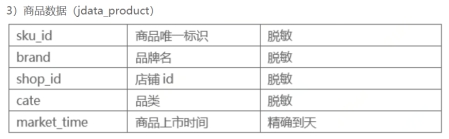
1.1.3 Jdata_product数据表
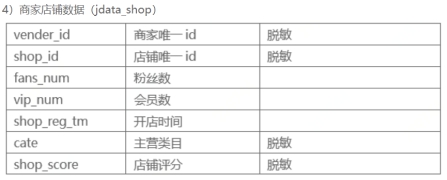
1.1.4 Jdata_shop数据表
1.1.5 jdata_user数据表
1.2 单变量分析
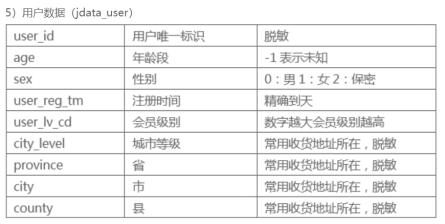
浏览数据: 2月份的数据由于处于春节期间,数据波动较大,3.27-3.28两日浏览数据存在大量缺失(不适宜做训练集),其余日期的浏览数量较为平稳。
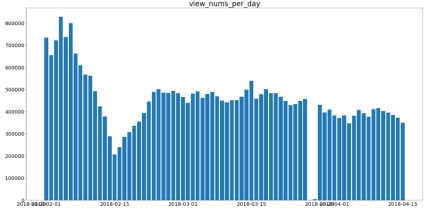
购买数据:购买数据也是受春节的影响,过年前后数据波动很大,3月之后购买趋于平稳,只有3月28号购买数量略有异常,较平常多一些
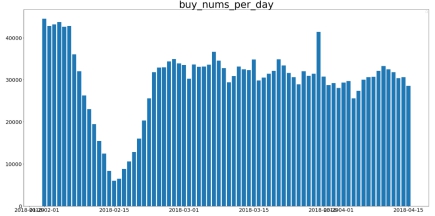
收藏、评论数据:除去春节的影响,整体数据较为平稳。
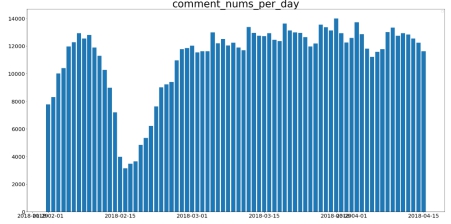
加购的数据:存在严重缺失,两个半月只有4.08-4.15才有加购数据
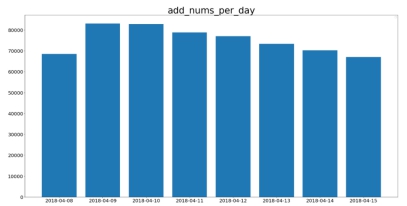
用户购买的时间周期: 通过分析用户购买的时间间隔(天),可以发现大部分用户购买的时间间隔都在20天以内。
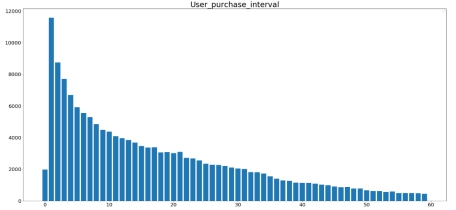
用户点击购买平均时差: 通过分析用户点击购买平均时差(天),可以发现大部分用户第一次点击到购买的时差在十天以内。
2、数据预处理
2.1处理 Missing Data
jdata_user用户信息表中的age采用中位数,sex,city_level,province,city,county,shop_reg_tm,jdata_shop.cate等采用众数进行填充。
2.2处理Time类数据
针对time类数据的分布广泛且无法作为数值型数据直接处理,故进行time数据分箱,有两种划分方案:一种是等值划分(按照值域均分),另一种是等量划分 (按照样本数均分)。我们这里选择等值划分,将特征按照时间大小均匀地划分为6个区间,即离散化为 1~6。
需要进行时间分箱操作的字段有:user_reg_tm, shop_reg_tm, market_time, 具体分箱细节如下图:

另为方便后续特征工程中时间滑窗工作,故将用户操作时间字段action_time转换成精确到天的Date类型。
2.3 离群值处理
在离群值的处理上,通过EDA的分析,我们发现3月前数据存在着较大的不稳定性,故训练集不采用这部分样本。
2.4类别型特征处理
由于离散特征在数值上没有具体含义,直接参与训练可能会影响分类性能,故我们采用了 One-Hot编码,得到了01特征,尽管针对于XGBoost来说可能不太需要One-Hot编码,但鉴于我们的类别范围较小,也取得了不错的效果。进行One-Hot的特征有sex,city_level,province,user_reg_tm,shop_reg_tm,market_time。
3、特征工程
由于用户行为对考察周购买的影响随时间减弱,根据上述的分析可知,用户在两周之前的行为对考察周是否购买的影响已经很小,故而只考虑距考察周两周以内的用户数据。
由于数据来源于平台电商,其特点是线上购买线下消费,猜测其购买行为具有一定的周期性,进一步猜测行为周期为两个星期,同时统计其前1/3/5/7/10天的各种行为。
由于问题已被明确为 U-C-S是否发生购买行为(标记label取{0,1])的分类问题,最终的特征数据均要合并到生成以 U-C-S 为index(key)的样本集上来。进一步地,如要考虑所有可能的 U-C-S ,必将面临组合爆炸的问题,所以这里只关注在距考察周两周以内出现过U-C-S 。
针对当前业务背景,我们团队考虑从user、cate、shop_id三大基本维度及其交叉组合入手进行特征构建,这里将所需构建的特征分为七大类:U、C、S、UC、US、CS、UCS,对每类分别结合行为次数、时间、排序等视角设计特征。考虑到样本规模,特征数量不宜太少,这里我们设计了约250个特征来进行该比赛的数据任务。
3.1基于用户的特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| u_b_count_in_n(n=1/3/5/7/10) | U类 | 用户在考察日前n天的行为总数计数 | 反映了user_id的活跃度(不同时间粒度:最近1天/3天/5天/7天/10天) | 5 |
| u_bi_count_in_n(i=1/2/3/4/5,n=1/3/5/7/10) | U类 | 用户在考察日前n天的各项行为计数 | 反映了user_id的活跃度(不同时间粒度),反映了user_id的各项操作的活跃度,折射出user_id的购买习惯 | 25 |
| u_b2_rate | U类 | 用户的点击购买转化率 | 反映了用户的购买决策操作习惯 | 1 |
| u_b1_diff_days | U类 | 用户的点击购买平均时间间隔 | 反映了用户的购买决策时间习惯 | 1 |
| u_jiange_mean | U类 | 用户购买的平均时间间隔 | 反映了用户的购买决策时间习惯 | 1 |
| u_b2_last_days | U类 | 最后一次购买距离考察周时间 | 反映了用户的购买决策时间习惯 | 2 |
3.2基于品类的特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| c_b2_rate | C类 | 品类的点击购买转化率品类的收藏购买转化率品类的评论购买转化率 | 反映了品类的购买决策操作习惯 | 3 |
| c_all_count | C类 | 品类下商品,品牌,店铺的数量 | 反映了品类的覆盖性 | 3 |
| c_u_count_in_n | C类 | 品类在考察日前n天的用户总数计数 | 反映了品类的热度(用户覆盖性) | 5 |
| c_bi_count_in_n | C类 | 品类在考察日前n天的各项行为计数 | 反映了品类的热度(用户停留性) | 25 |
| c_b2_count | C类 | 品类被购买的频次 | 反映了品类的受欢迎度 | 1 |
| c_comments_counts | C类 | 品类的评论 | 反映了品类的评论好坏 | 3 |
| c_new_item_count | C类 | 品类下新品的数量 | 反映了品类的新品情况 | 1 |
3.3基于店铺的特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| s_b2_rate | S类 | 店铺的点击购买转化率店铺的收藏购买转化率店铺的评论购买转化率 | 反映了店铺的购买决策操作习惯 | 3 |
| s_all_count | S类 | 店铺下品类的数量和商品的数量 | 反映了店铺的覆盖性 | 2 |
| s_u_count_in_n | S类 | 店铺在考察日前n天的用户总数计数 | 反映了店铺的热度(用户覆盖性) | 5 |
| s_bi_count_in_n | 店铺在考察日前n天的各项行为计数 | 反映了店铺的热度(用户停留性) | 25 | |
| s_b2_count | S类 | 店铺被购买的频次 | 反映了店铺的受欢迎度 | 1 |
| s_comments_counts | S类 | 店铺的评论 | 反映了店铺的评论好坏 | 3 |
| s_new_item_count | S类 | 店铺下新品的数量 | 反映了店铺的新品情况 | 1 |
| s_b2_diff_day | S类 | 店铺的点击购买平均时差 | 反映了店铺的购买决策时间特点 | 1 |
| shop_info | S类 | 店铺的评分,粉丝数,会员数,开店时间 | 反映了店铺的基本实力 | 4 |
3.4基于用户与品类的组合特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| uc_b2_rate | UC类 | 用户对品类的点击购买转化率、收藏购买转化率、评论购买转化率 | 反映了用户对品类的购买决策操作习惯 | 3 |
| uc_b2_diff_day | UC类 | 用户的点击购买平均时差 | 反映了用户的购买决策时间习惯 | 3 |
| uc_bi_last_day | UC类 | 用户-品类对各项行为上一次发生距考察日的时差 | 反映了用户-品类的活跃时间特征 | 4 |
| uc_b_count_in_n | UC类 | 用户-品类对在考察日前n天的行为总数计数 | 反映了品类的热度(用户覆盖性) | 5 |
| uc_bi_count_in_n | UC类 | 用户-品类对在考察日前n天的各项行为计数 | 反映了品类的热度(用户停留性) | 25 |
| uc_b_count_rank_in_n_in_u | UC类 | 用户-品类对的行为在用户所有商品中的排序 | 反映了用户对品类的行为偏好 | 5 |
| uc_active_days | UC类 | 用户-品类对考察周前一段时间内做出行为的天数 | 反映了用户对品类的活跃度 | 1 |
3.5基于用户与店铺的组合特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| us_b2_rate | US类 | 用户对店铺的点击购买转化率、收藏购买转化率、评论购买转化率 | 反映了用户对店铺的购买决策操作习惯 | 3 |
| us_b2_diff_day | US类 | 用户的点击购买平均时差 | 反映了用户的购买决策时间习惯 | 3 |
| us_bi_last_day | US类 | 用户-店铺对各项行为上一次发生距考察日的时差 | 反映了用户-店铺的活跃时间特征 | 4 |
| us_b_count_in_n | US类 | 用户-店铺对在考察日前n天的行为总数计数 | 反映了用户对店铺的热度(用户覆盖性) | 5 |
| us_bi_count_in_n | US类 | 用户-店铺对在考察日前n天的各项行为计数 | 反映了用户对店铺的热度(用户停留性) | 25 |
| us_b_count_rank_in_n_in_u | US类 | 用户-店铺对的行为在用户所有商品中的排序 | 反映了用户对店铺的行为偏好 | 5 |
| us_active_days | US类 | 用户-店铺对考察周前一段时间内做出行为的天数 | 反映了用户对店铺的活跃度 | 1 |
3.6基于品类与店铺的组合特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| cs_u_rank_in_c | CS类 | 品类下店铺中的用户人数排序 | 反映了店铺在品类中的热度排名(用户覆盖性) | 1 |
| cs_item_count | CS类 | 品类-店铺下商品的数量 | 反映了品类下店铺的商品覆盖性 | 1 |
| cs_b2_count | CS类 | 品类-店铺对被购买的频次 | 反映了品类-店铺的热度 | 1 |
| cs_b_rank_in_s | CS类 | 品类下店铺中的行为总数排序 | 反映了店铺在品类中的热度排名(用户停留性) | 1 |
| cs_b2_rank_in_s | CS类 | 品类下店铺中的销量排序 | 反映了店铺在品类中的销量排名(店铺销量) | 1 |
| cs_b2_rate | CS类 | 类别下店铺的点击购买转化率,收藏购买转化率,评论购买转化率 | 反映了品类-店铺的购买决策操作特点 | 3 |
| cs_active_days | CS类 | 品类-店铺对考察周前一段时间内被做出行为的天数 | 反映了品类-店铺的活跃度 | 1 |
3.7基于用户与品类-店铺的组合特征
| 特征名称 | 所属类别 | 特征含义 | 特征作用 | 特征数量 |
|---|---|---|---|---|
| ucs_b2_rate | UCS类 | 用户对品类-店铺对的点击购买转化率、收藏购买转化率、评论购买转化率 | 反映了用户对品类-店铺对的购买决策操作习惯 | 3 |
| ucs_b2_diff_day | UCS类 | 用户-品类-店铺对的点击购买平均时差 | 反映了用户的点击购买决策时间习惯 | 1 |
| ucs_bi_last_day | UCS类 | 用户-品类-店铺对各项行为上一次发生距考察日的时差 | 反映了用户-店铺的活跃时间特征 | 3 |
| ucs_jiange_mean | UCS类 | 用户-品类-店铺平均购买时间间隔 | 反映了用户-品类-店铺对的购买决策时间习惯 | 1 |
| ucs_ac_nunique | UCS类 | 用户-品类-店铺的购买频次 | 反映了用户对品类-店铺对的喜爱度 | 1 |
| ucs_b_count_in_n | UCS类 | 用户-品类-店铺对在考察日前n天的行为总数计数 | 反映了用户对店铺的热度(用户覆盖性) | 5 |
| ucs_bi_count_in_n | UCS类 | 用户-品类-店铺对在考察日前n天的各项行为计数 | 反映了用户对店铺的热度(用户停留性) | 25 |
| ucs_b_count_rank_in_n_in_u | UCS类 | 用户-品类-店铺对的行为在用户所有商品中的排序 | 反映了用户对品类-店铺的行为偏好 | 5 |
| ucs_active_days | UCS类 | 用户-品类-店铺对考察周前一段时间内做出行为的天数 | 反映了用户对品类-店铺对的活跃度 | 1 |
3.8特征选择
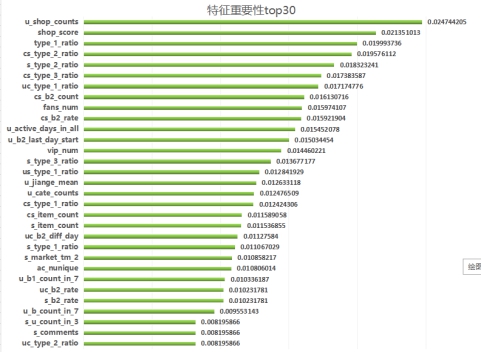
前面经过我们的头脑风暴,基于原始特征生成了大量统计型特征,比值型特征,时间型特征以及一些排序型特征。全部加起来有差不多有300维,这么多维特征一方面可能会容易导致过拟合,另外一方面会增大模型的开发成本,增大训练的时间。因此需要用特征选择来降低特征维度。特征选择的方法很多:最大信息系数(MIC)、皮尔森相关系数(衡量变量间的线性相关性)、正则化方法(L1,L2)、基于模型的特征排序方法。比较高效的是最后一种方法,即基于学习模型的特征排序方法,这种方法有一个好处:模型学习的过程和特征选择的过程是同时进行的,因此我们采用这种方法。基于决策树的算法(如 random forest,boosted tree)在模型训练完成后可以输出特征的重要性,在这个比赛中我们用了 xgboost 来做特征选择,xgboost 是 boosted tree 的一种实现,效率和精度都很高,在各类数据挖掘竞赛中被广泛使用。
4、算法建模
4.1候选集的构建
由于线上需要我们预测考察周4.16-4.22是否购买,因此在线下我们可以假设4.09-4.15这一周未知,用4.09-4.15这一周之前的数据来提取用户集和特征。同时,为了扩大样本量,我们进行了滑窗采样,分为三组训练集,一组一组验证集,一组测试集,如下图方案二所示:
同时,为了保证线上线下一致性,我们取了标签区间前2周购买过目标品类和店铺的用户集作为我们构建训练数据的用户集合,标签区间前n天的时间提取特征。
由之前的分析我们发现用户购买行为中2月份的数据存在较大波动, 故为了排除春节(02-16)/元宵(03-02)节假日效应的余波,我们选择数据时尽量选择离考察周最近的一些数据进行训练与预测,另外对行为数据中的浏览、关注、评论、加购数据进行分析,不幸的发现,2018-04-08之前的加购数据全部缺失,加购数据存在天数只有2018-04-08到2018-04-15,同时3.27-3.28的浏览数据存在大量缺失,经过测试,27,28号的浏览数据的缺失会影响到预测的准确性,故决定删除该部分数据样本。因此,这里我们分析了两种方案,结合模型的训练耗时和实际测试的效果,我们的总体方向都是使用考察周前两周的数据进行训练,如下图所示。

4.2 模型选择
基于树的算法通常抗噪能力更强,我们很容易对缺失值进行处理。除此之外,基于树的模型对于 categorical feature 也更加友好。Tree boosting(树提升)已经在实践中证明可以有效地用于分类和回归任务的预测挖掘。
在模型选择上,我们队伍使用XGBoost作为主要模型。在比赛前期我们团队尝试使用XGBoost,LightBGM,逻辑回归等算法进行训练,发现未经过多调参的基础上,XGBoost模型训练出来的效果远比其他模型好,同时仰赖于XGBoost对于特征重要性有良好的评估效果,故一开始没有在模型选择上进行过多的纠结,一直采用XGBoost进行训练。
4.3 模型训练&验证&测试
在前期的尝试中,由于对加购物车数据的执念,一直坚持只使用了方案一进行训练,在训练过程中随机划分了20%左右样本进行作为验证集,采用’binary:logistic’方式输出目标预测概率,评估指标采用’auc’,训练轮次500次。A榜结束前一周成绩一直徘徊在0.055左右,采用grid search对模型参数进行微调,鉴于效果没有明显提升以及线上提交次数的限制,转而团队继续对数据进行分析挖掘更多的特征。由于后续几个强特(如购买时间间隔等)的加持,A榜结束时,团队成绩上升到0.0583左右,B榜提交相同文件,成绩大概0.06左右,我们猜测B榜数据量相对多一些。进入B榜后,由于在交流群中讨论时意外地发现一些细节:前排有大佬竟完全未使用购物车数据也能有很好的训练效果,故我们决定抛开执念,重新构造训练集,由于没有购物车数据的困扰,数据可选择范围变开阔,我们重新构造了方案二的训练集,但是此时B榜的提交验证机会只剩两次,兼顾保守与自信,我们并没有完全摒弃之前的数据集与模型,而是采用了模型融合的方式。故我们团队的模型训练,验证以及测试方式主要分为以下两种:
(1)在需要考虑加购数据时,我们能够利用的加购物车数据仅为4月8日一天的加购记录。对应的在测试集中的特征构建时我们也仅使用4月15日的加购数据。其中抽样少量样本做线下验证。
(2)在不考虑加购物车数据的情况下,我们构造了三个训练集和一个测试集,其中前期训练时使用前两个训练集分别单独训练,使用第三个训练集做验证集,同时分别用训练好的模型对验证集进行预测,由此测试确定需要提交的正样本个数所对应的的概率阈值(有验证集可知,提交样本数在一万左右,成绩最优)。确定概率阈值之后,接着把验证集也加入到训练中。
第三部分:关键代码
1、算法框架
1.1 方案一算法框架
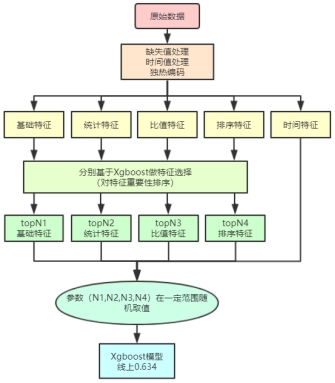
在基于原始特征得到统计特征、比值特征、排序特征、时间特征之后,我们分别对这几种特征进行特征选择,特征选择的方法前面已有介绍,基于 xgboost 来做,训练 xgboost 的过程就是对特征重要性进行排序的过程。得到特征的重要性之后,我们可以保留最重要的top N1个原始特征,top N2 个统计特征,top N3 个比值特征,top N4 个排序特征。(时间特征由于比较重要,所以不做特征选择)。
参数(N1,N2,N3,N4)是通过实验来确定最优的取值,每一维度的特征先训练一个简单的Xgboost模型,输出排序后的特征重要性,再跟特征重要性进行特征选择,重新训练模型,获取比较好的取值。
1.2 线下验证方案算法框架
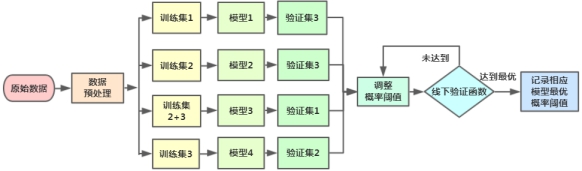
本次比赛的数据集正负样本严重不平衡,正负样本比例达到1:130左右,因此难以确定比较好的概率输出阈值。本团队曾尝试过使用时间划窗去获取更多的正样本然后加到原始模型中以增大正样本的数量,但是发现效果不佳,估放弃这种方案。
同时由于线上提交次数有限制,无法靠线上结果来验证最优提交结果数和概率阈值。因此我们团队通过时间划窗,构建了多个训练集和验证集,同时构造了线下验证函数,通过交叉验证的方式,获取到每个模型的最优概率阈值,最终确定提交结果数1万左右为最优。
1.3 最终方案算法框架
本团队最终的方案采用了多XGBoost+Bagging的结果融合方式,在融合之前我们采用方案二中训练集1,2,3分别训练,并各自做交叉验证得到每个模型恰当的概率阈值和正样本个数,然后分别采用方案一中有加购的训练集和无加购的训练集1,2,3,2+3分别进行模型训练并预测考察周的购买情况以及输出正样本个数,最后采用Bagging投票器思想对5个预测文件进行投票,采用少数服从多数(至少3票)的投票规则,输出最终的提交文件,线上最终得分0.0673, 相对方案一单模型最好成绩提升4个千分点。

2、模型性能
比赛是一个不断尝试和思考的过程,数据处理、特征工程、特征选择、模型训练也是一个不断迭代更新的过程
由于每次成绩的显著提升,基本上都是在找到新的强特之后,若以分数作为参考系,提升进程大概如下:
| 版本 | 线上分数 | 改进说明 |
|---|---|---|
| V1 | 0.054 | 加入基础的7类特征(用户属性U,品类C,店铺S以及三者的轻度交叉组特征合) |
| V2 | 0.0583 | 继续围绕U,C,S,UC,US,UCS这七个维度的特征进行优化和扩展 |
| V3 | 0.0634 | 新加入U、UC、US、UCS点击购买距离考察周时间间隔以及平均购买周期等时间型特征,构造了验证集和验证函数,确定模型较为恰当的阈值 |
| V4 | 0.0673 | 对方案1和2的XGBoost预测结果进行投票融合 |
3、关键代码
由于需要预测的是用户未来7天内对某个目标品类下某个店铺的购买意向,因此跟时间类相关的信息显得尤为重要,用户其购买行为具有一定的周期性,所以我们选择对应日期对应时间段的信息进行特征的构建,关键的代码如下:
用户购买时间间隔&用户最近购买距离考察周时间
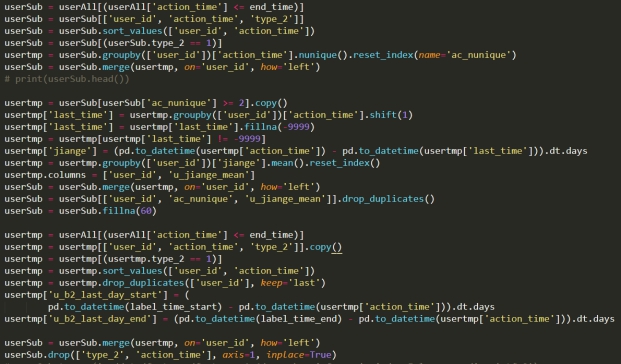
用户点击购买平均时差&用户最近点击距离考察周时间
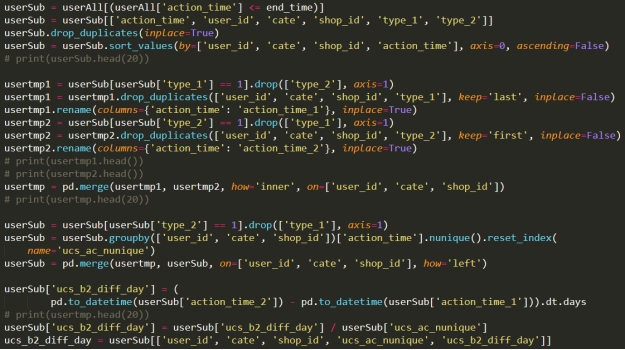
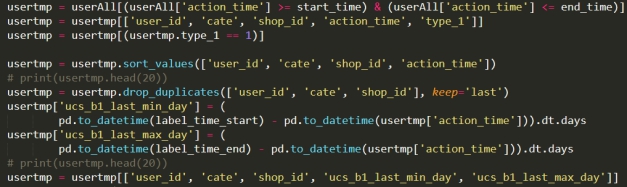
第四部分:比赛经验总结
本次大赛没有直接提供训练集对应标签,需要参赛者根据业务数据的理解进行训练集、验证集以及测试集的构建,赛题具有相当的灵活性,但也增加了赛题的难度。针对需要解决的问题和数据特征,我们队伍主要从四个方面进行处理:数据预处理,标签数据集划分,特征工程,模型训练和融合。
对于这次比赛,我们团队有很多收获,也有很多遗憾,首先,在模型选择方面考虑的不多,由于计算资源有限以及平时比较忙的原因(团队只有两个人参与算法编码),没有进行更多的模型尝试和调参,比赛初期有尝试过其他模型,但是由于效果不好,缺乏时间去调参,就放弃了使用其他模型的想法,比赛后期,基本只用XGBoost单模型进行训练。同样,正是由于模型这一块使用的单模,所以我们团队的时间大部分放在了挖掘更有效的特征上面,因此在特征构造这一块我们考虑相对是比较全面的,单模型跑出来的结果也不错。
一些比赛技巧上我们也有待加强,例如比赛前期我们团队一直使用的是有加购的数据,但是有加购的数据存在缺失,无法进行时间划窗采样更多的数据,导致线下验证函数不准确,无法获得比较优的阈值。 总的来说特征为王,例如比赛前期我们团队一直使用基础特征+计数型特征+排序型特征+比值型特征的方式进行模型训练,时间类特征挖掘的比较少,虽然也取得不错的成绩,但是与前排大佬们还是有一段距离。在比赛后期,我们团队侧重于时间类特征的构造,挖掘了很多强特,在B榜结束前终于冲进了前20。同时提交的结果数也是一个影响线上成绩的一个关键因素,由于每次评测次数有限,所以一个可靠的线下验证方案尤为重要。
限于时间、精力和硬件资源的限制,本次比赛并未尝试使用深度学习相关技术,从赛题题意上来说是可以进行尝试的。